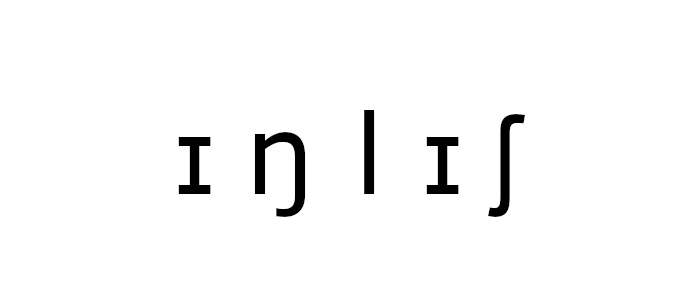Forced alignment is sometimes more art than science, but let’s try to establish some rules of thumb for how much data you might need when aligning a corpus
Let’s take a closer look at some new features in MFA 2.0, multilingual IPA and speaker-specific dictionaries and how they can be used to align multi-dialectal and multilingual corpora
Want to bootstrap and clean up a new dictionary? This tutorial covers my experience creating a new IPA dictionary for English using Montreal Forced Aligner’s 2.0 functionality
STRAIGHT is a program that analyzes speech, decomposes it into source and filter characteristics, and then recombines it after some manipulation or interpolation. This tutorial is more of a practical guide for using STRAIGHT to create various synthetic speech