Update on Montreal Forced Aligner performance
[TOC]
Overview ¶
The Montreal Forced Aligner version 1.0 released on May 18, 2017, with the Interspeech paper appearing that year as well. In the four years since, it has changed considerably and with the eventual release of 2.0 once it feels a bit more stable, I thought I’d take a moment to analyze some performance experiments that I’ve been playing around with.
In addition to features internal to MFA, I also want to take a look at how the performance compares to FAVE and MAUS , as the other two standards in the field. At some point I’d like to get LaBB-CAT ’s aligner set up, but that’s a bit more involved than the other two and leverages the same pretrained acoustic model as FAVE. If there are other aligner systems out there that I should benchmark, let me know.
Methodology ¶
Dataset ¶
The benchmark dataset is derived from the Buckeye corpus , the same as the 2017 Interspeech paper , where utterances are extracted with text transcriptions into small chunks of audio that are fed into the respective aligners.
-
33,370 extracted chunks
-
40 speakers
-
16.5 hours total duration
I’m expanding the benchmark of the Buckeye corpus . The word distance and CVC datasets are the same, but I’m also interested in the larger phone accuracies outside the more controlled CVC dataset. I’ll cover the measures pulled from the corpus more in depth as they come up in the results section.
Procedure ¶
|
Aligner ID |
Phone set |
Alignment procedure |
|---|---|---|
|
FAVE |
ARPABET |
align |
|
MAUS |
X-Sampa |
align |
|
MFA English |
ARPABET |
align |
|
MFA English adapted |
ARPABET |
adapt |
|
MFA default train |
ARPABET |
train_and_align |
|
MFA English IPA |
IPA |
align |
|
MFA English IPA adapted |
IPA |
adapt |
|
MFA English IPA train |
IPA |
train_and_align |
The MFA runs represent a cross between training procedure and pronunciation dictionary. Training procedures are as follows:
-
align: Performs an initial alignment and then computes speaker-adapted features for a second pass alignment -
adapt: Performs an initial alignment with an acoustic model followed by 3 rounds of speaker adaptation, alignment and re-estimation of the model -
train_and_align: Performs the default training regime in MFA 2.0, which starts with a subset of utterances to train a monophone model, expands the subset to train a triphone model, performs LDA calculations and two rounds of speaker adaptation to refine the input features over increasing sizes of subsets.
For pronunciation dictionaries, the ARPABET dictionary is the standard one provided via MFA’s download command. The IPA
dictionary was created recently (see
the blog post about it
for
more details about its creation). Additionally, I used a newly introduced
multilingual_ipa
mode that does some
normalizations to the IPA pronunciations to remove some unnecessary (for the aligner) variation (blog post coming soon!
In the meantime refer
to
the docs
). In all cases
of pretraining, the audio data is from LibriSpeech, just the pronunciation dictionaries differ.
Accuracy Results ¶
Let’s begin with the replication of Interspeech paper. First step is looking at the word boundary errors. So for every word boundary find the absolute distance between the manual annotation in the Buckeye corpus and the aligner generated annotations. The plot below shows these by the aligner and split into whether the boundary is next to a silence or not, as that heavily influences accuracy.

MFA generally looks to be performing well! One interesting thing to highlight is that aligners trained on the Buckeye corpus itself handle boundaries next to pauses better (though still not the same degree as within continuous speech). This benefit is likely due to the silence models being trained on the actual audio, whereas the silence models for the other MFA models are trained on LibriSpeech, which is overall less noisy.
Next up we have the CVC phone boundaries calculated in the Interspeech paper. To generate these, we took a list of 534 CVC word types in the Buckeye corpus (I believe originally from Yao Yao’s dissertation ), words like base , choose , gone , young , etc. For every token that matched, first we check whether the surface form from the manual annotation and the aligner annotation have three phones, and skip if they don’t. This avoids instances where a consonant is deleted. Following the check, we extract 4 boundaries:
-
beginning of the initial consonant
-
between the initial consonant and the vowel
-
between the vowel and the final consonant
-
at the end of the final consonant

We can see that the word boundaries have the highest error (also note that we’re not controlling for pause boundaries here, so that’s going to make these a bit messier). General trends are also that CV transitions are more accurate than VC transitions, even across aligners. Somewhat surprising is that the pretrained IPA English model is doing as well/better than the adapted and trained versions.
For completeness, here are the same summary statistics from the above plots.
| Aligner | Word boundaries | Phone boundaries | ||
|---|---|---|---|---|
| mean (ms) | median (ms) | mean (ms) | median (ms) | |
| FAVE | 24.8 | 16.6 | 19.2 | 12 |
| MAUS | 29.6 | 15 | 20.5 | 10.4 |
| MFA English | 23.6 | 15.4 | 16.3 | 11 |
| MFA English adapted | 23.4 | 15 | 16.6 | 11.1 |
| MFA default train | 21.1 | 14.1 | 16.9 | 11.3 |
| MFA English IPA | 21.4 | 14.1 | 15.8 | 9.9 |
| MFA English IPA adapted | 21.6 | 14.3 | 16.4 | 10.3 |
| MFA English IPA train | 20.2 | 14 | 16.5 | 10.7 |
So that replicates the basic findings of the Interspeech paper. Note that the numbers for
MFA
english
(in the
Interspeech paper labelled as
MFA-LS
) and
MFA
default
train
(
MFA-Retrained
in the Interspeech paper) have actually
improved very slightly from MFA 1.0 to 2.0.
MFA
english
went from 24.1 ms mean word boundary distance to 23.6 ms, 17
ms mean phone boundary distance to 16.3 ms.
MFA
default
train
went from 22.6 ms mean distance for words to 21.1 and
from 17.3 ms to 16.9 ms for phone distance.
So that’s all cool, but the main reason I really wanted to re-explore this space is to come up with some better measures for actually measuring alignment accuracy. The phone boundary measures after all cover just CVC words, are a very small subset of total words in the Buckeye corpus, and pointedly ignore pronunciation variation in order to make things as controlled as possible. I think we can do better.
So the algorithm that I’ve done here is still a work in progress, but I think it’s pretty promising. The basic idea is that we want to align intervals in different transcripts (haha, aligning the alignments) based on how close those intervals begin and end (i.e., if they occupy the same space in the audio file, they’re likely the same segment). We also want to incorporate some very basic phone-to-phone mapping between the different phone sets to make sure it’s not entirely based off the timing, because the identity of phones is important too for evaluating whether an alignment is good.
The Python code is something like this (I’ll describe it more in words after the code if you want to skip that):
:::python
import re
from Bio import pairwise2
import functools
MATCH_SCORE = 0
MISMATCH_SCORE = 2
GAP_START_SCORE = -5
GAP_CONTINUE_SCORE = -5
def silence_check(phone):
return phone in {'sp', '<p:>', '', None}
def compare_labels(ref, test, aligner_name):
if 'ipa' in aligner_name:
mapping = ipa_mapping
elif 'maus' in aligner_name:
mapping = maus_mapping
else:
mapping = arpa_mapping
if re.match(r'[a-z]+[0-9]', test):
if ref == test[:-1].lower():
return MATCH_SCORE
else:
return MISMATCH_SCORE
if ref == test:
return MATCH_SCORE
if test in mapping and mapping[test] == ref:
return MATCH_SCORE
ref = ref.lower()
test = test.lower()
if ref == test:
return MATCH_SCORE
return MISMATCH_SCORE
def overlap_scoring(firstElement, secondElement, aligner_name):
begin_diff = abs(firstElement.minTime - secondElement.minTime)
end_diff = abs(firstElement.maxTime - secondElement.maxTime)
label_diff = compare_labels(firstElement.mark, secondElement.mark, aligner_name)
return -1 * (begin_diff + end_diff + label_diff)
def align_phones(ref, test, aligner_name):
ref = [x for x in ref]
test = [x for x in test]
score_func = functools.partial(overlap_scoring, aligner_name=aligner_name)
alignments = pairwise2.align.globalcs(ref, test,
score_func, GAP_START_SCORE, GAP_CONTINUE_SCORE,
gap_char=['-'], one_alignment_only=True)
overlap_count = 0
overlap_sum = 0
num_insertions = 0
num_deletions = 0
for a in alignments:
for i, sa in enumerate(a.seqA):
sb = a.seqB[i]
if sa == '-':
if not silence_check(sb.mark):
num_insertions += 1
else:
continue
elif sb == '-':
if not silence_check(sa.mark):
num_deletions += 1
else:
continue
else:
overlap_sum += abs(sa.minTime - sb.minTime) + abs(sa.maxTime - sb.maxTime)
overlap_count += 1
return overlap_sum / overlap_count, num_insertions, num_deletions
So what it does is use
biopython
’s pairwise sequence alignment algorithm with a custom match/mismatch function. The
score that we give to match/mismatch is not fully based on the label of the phone (though if it does not match, it gets
a base score of -2 vs 0 for if it does match). There are three mappings listed above (but not defined just because
they’re so long, I’ll provide tables in the appendix if you’re curious). These basically transform “known” or “
unambiguous” phones from X-Sampa, IPA and ARPABET into Buckeye’s specific phone set. In addition to the label match, we
also calculate the distance from the reference boundaries to the corresponding aligner-generated boundaries, in order to
locally constrain the alignment. The last parameter is the gap scores, which specify the penalty for inserting skips in
one of the sequences, either for insertions or deletions. The value of -5 for both seems to work pretty well for this
particular case. To illustrate the output from running with a FAVE alignment:
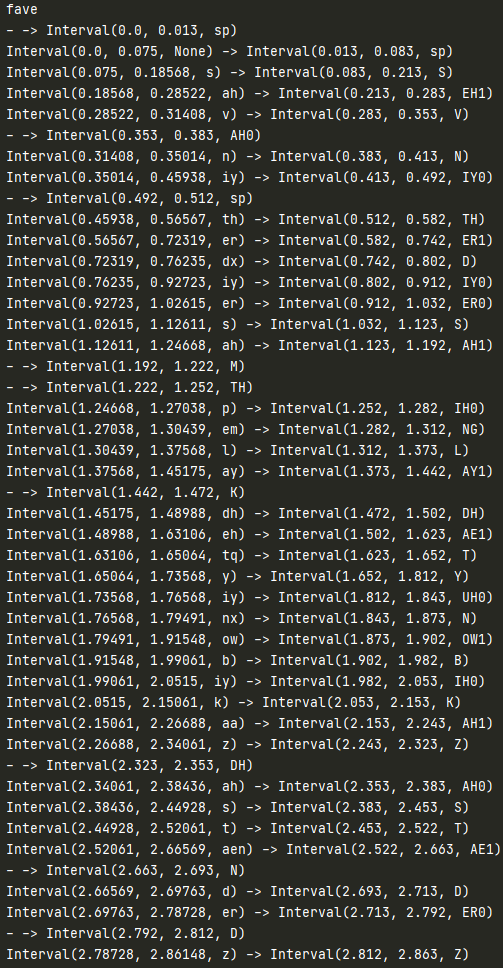
One final thing to note is that we’re basically ignoring any mismatches due to silences, so not inserting silence is not penalized per se.
Onto the actual results! Well, ok, before that, a note about some removals. In analyzing the data, I found that MAUS
for some reason phonemetized
yknow
as
/i:keIkeIkeIkeI/
. I’m not really sure where this is coming from, but it’s
fairly common in the Buckeye transcriptions and resulted in an inflated number of insertions. So for the following
analysis, any utterance with
yknow
in it has been removed (2,575 utterances of 33,166 total utterances).
To begin with, let’s take a look at the phone boundary errors.

Even removing the yknow utterances, MAUS is still having some issues here, which is a little weird because we weren’t seeing these disparities show up this much in the word boundary or CVC datasets. To dig a little deeper, if we look at this same data faceted by speaker, we can see a lot of these issues are driven by a few speakers.

Particularly
s01
,
s13
,
s15
,
s20
,
s23
,
s24
,
s27
, and
s36
are contributing more so than others to the
increased error rate. I don’t know for sure what’s causing the issues, it might be something about vocal quality,
recording quality, or pronunciation generation that’s affecting those more so than others.
Looking at the other measures of quality, we can see that MAUS is performing the best when it comes to insertions (
when
yknow
isn’t counted…). Additionally, you can see that IPA versions of MFA are inserting less, which makes sense
because the ARPABET versions have multiple characters for syllabic consonants (i.e.
/l̩/
like in
bottle
is
transcribed as
AH0
L
).

Finally, in terms of deletions, these are less common than insertions overall. I think the primary reason for this is that our reference is the surface form annotations in the Buckeye corpus. These surface forms are generally pretty reduced and close to the spoken form, so our the ground truth is not citation forms. Of note, FAVE tends to insert much more than it deletes, which is due to its reliance on CMU dictionary’s citation forms. MAUS on the flip side tends to delete more than it inserts, likely due to the post-lexical pronunciation modelling that it does. IPA versions of MFA tend to delete more than the ARPABET versions, I haven’t fully analyzed this, but my guess here is that some of these phones that are still in the Buckeye surface form transcriptions get deleted in the IPA version because they’re shorter than the minimum duration for a phone (30ms), so the cost of deleting is less for it.

Summing up ¶
MFA’s not looking too shabby! It’s nice to see the improvements made in the transition to version 2.0 having concrete improvements. Not surprisingly, the IPA dictionary is showing some good performance specifically with the Buckeye dataset due to similarities in the syllabic consonants. It’s not as phonetic as the Buckeye phone set, but with the limitation of 30ms minimum on phones, it can’t really quite get there.
Now, of course, the huge caveat to all this is that it’s English. I’d be super curious to see how performance differs across languages, but I’m not aware of too many manually corrected datasets out there that could serve as additional benchmarks, but I’d be curious to see how the methodology here stacks up.
Appendix ¶
Benchmark performance metrics ¶
The accuracy metrics above are the primary point of this point, but I do want to touch on the timing benchmarks done as part of this, as speed can be a consideration as well. The below graph shows how long each of the MFA runs took. Note that I didn’t benchmark the FAVE or MAUS cases, since they were not really optimized for this use case, but they each took several hours to generate, FAVE about a day’s worth of run time, MAUS about 6 hours of manual upload and download via WebMAUS.
For the MFA runs, the following system was used:
-
12 cores
-
i9-10900KF at 3.7 GHz
-
32 GB of RAM
-
Windows installation of MFA

The
align
runs are the quickest, coming in at under 15 minutes to generate all the TextGrids. The
adapt
runs are the
next fastest, at a little over half an hour to do a couple of adaptation iterations and then align. Training
unsurprisingly takes the longest at just around an hour and a half.
The next metrics are the final average per-frame log-likelihood on the final alignment. While I haven’t had success
using this kind of metric on a per-utterance basis to figure out what files have issues like missing words, it does seem
generally useful for gauging how well an alignment system is doing. Compare the below figure with the above phone
boundary error rates across the full corpus. The log-likelihood for
MFA
English
and
MFA
English
adapted
are much
lower than the other runs, and these are exactly the runs that have higher phone boundary error rate above. So at least
a sanity check that this can be used as a proxy measure for when human annotations aren’t available to compare against.

Phone mappings ¶
maus_mapping = {
'dZ': 'jh',
'Z': 'zh',
'6': 'er',
'tS': 'ch',
'S': 'sh',
'Q': 'aa',
'A': 'aa',
'A:': 'aa',
'Q:': 'aa',
'{': 'ae',
'{:': 'ae',
'E': 'eh',
'@': 'ah',
'V': 'ah',
'V:': 'ah',
'D': 'dh',
'T': 'th',
'e': 'ey',
'e:': 'ey',
'aU': 'aw',
'@U': 'ow',
'oU': 'ow',
'eI': 'ey',
'i:': 'iy',
'u:': 'uw',
'u': 'uw',
'U': 'uh',
'O:': 'ao',
'O': 'ao',
'o': 'ow',
'o:': 'ow',
'aI': 'ay',
'OI': 'oy',
'oI': 'oy',
'n': 'en',
'm': 'em',
'l': 'el',
'i': 'iy',
'j': 'y',
'I': 'ih',
'?': 'tq',
'N': 'ng',
'h': 'hh',
}
ipa_mapping = {
'ʔ': 'tq',
'i': 'iy',
'h': 'hh',
'iː': 'iy',
'ɡ': 'g',
'ɚ': 'er',
'ɝ': 'er',
'ɝː': 'er',
'3`': 'er',
'dʒ': 'jh',
'tʃ': 'ch',
'ʒ': 'zh',
'ɑ': 'aa',
'ɑː': 'aa',
'ʊ': 'uh',
'ɛ': 'eh',
'oʊ': 'ow',
'aʊ': 'aw',
'aɪ': 'ay',
'ɔ': 'ao',
'ɔː': 'ao',
'ɔɪ': 'oy',
'u': 'uw',
'uː': 'uw',
'æ': 'ae',
'eɪ': 'ey',
'ð': 'dh',
'ʃ': 'sh',
'ɹ': 'r',
'j': 'y',
'θ': 'th',
'ə': 'ah',
'ŋ': 'ng',
'ʌ': 'ah',
'n̩': 'en',
'm̩': 'em',
'l̩': 'el',
}
arpa_mapping = {
'N': 'en',
'M': 'em',
'L': 'el',
}