Speaker dictionaries and multilingual IPA
[TOC]
Overview ¶
There’s a couple of new features in Montreal Forced Aligner 2.0 that I’d like to cover in a bit more depth to showcase how they might be useful for other people’s workflows, namely speaker-specific dictionaries and the multilingual IPA mode . I conceived of these in the context of a multilingual aligner that uses IPA pronunciation dictionaries to generate “pretty good” alignments for languages where you don’t have much annotated data yet, but want to get to reasonable boundaries for acoustic analysis.
There are already aspects of MFA that play into the idea of adaptation to new contexts, namely phone clustering and speaker adaptation. Phone clustering arose to combat the problem of sparsity in creating triphone models. In monophone models (i.e. those that do not take phonological context into account), you’re likely to see very good representation for each phone (with the exception perhaps of phones in loanwords). Once you move to triphone models and start to look at the preceding and following phones, you’ll hit problems with seeing all combinations. For a word like “Sri” in “Sri Lanka”, we’ll have many instances of
/s/
,
/ɹ/
, and
/i/
occurring throughout a corpus, but very few instances of
/sɹi/
as a triphone. To solve the issue of these low counts, phone clustering looks to combine similar model states across triphones. So in
/sɹi/
, the
/ɹ/
can leverage
/ɹ/
in other more common phonological contexts. You can also think of it as similar to modelling allophonic variation, as the stops in triphones like
/ɪti/
and
/ɪdi/
can be modelled with the same state capturing a flap, even if it’s not explicitly coded in the pronunciation dictionary.
The speaker adaptation step transforms features from an initial alignment in a speaker independent feature space to a speaker normalized feature space. You can think about this a bit like vowel space normalization, where the vowel space for two people of the same dialect in raw acoustic formant space don’t correspond, but normalizing the formants yields a more consistent vowel space for a dialect.
We can apply this logic to the multilingual IPA mode. Say two languages both have a sound that’s transcribed
/ɛ/
, speakers of these two languages will produce it slightly (or maybe even not so slightly) different. But with the phone clustering and speaker transforms, we can (probably) model both
/ɛ/
phones pretty well. At least to the point that good forced alignments are possible, because forced alignment is a much more constrained problem space than something like large vocabulary ASR.
Introducing speaker dictionaries ¶
So that’s the MFA 1.0 feature set that could support multilingual models. However there’s a couple more issues to tackle to make it a more manageable problem. The first is speaker dictionaries. There is an assumption in ASR of one pronunciation dictionary to rule them all. That is, there is a singular lexicon that all possible pronunciations should be drawn from. This assumption kinda works okay with the above methods for dealing with variability, since it can cover a decent chunk of speaker variability (and some dialect variability), but once you get into the realm of deletions or very different pronunciations it starts to fall apart. Dialects in English that are r-ful versus those that are r-less are going to run into confusions for words like “center” (
/s
ɛ
n
t
ɚ/
vs
/s
ɛ
n
t
ə/
). It is
possible
that the system will learn and output the correct variant, but if we can constrain the system to only produce correct variants per dialect/speaker, then it’s just much easier for the system to learn the acoustic models overall.
The problem gets even larger when you consider two languages that have radically different phonologies but lots of shared vocabulary. A shared lexicon between English and French will have a decent overlap in orthographical forms, but the pronunciations for those shared words are going to be completely different. As a concrete example, compare “centre” between French (
/s
ɑ̃
t
ʁ
ə/
) and British English (
/s
ɛ
n
t
ə/
). Mistakenly selecting the French pronunciation for an English speaker will result in no
/n/
being modelled, and might lead to issues later on when you do have a sequence of an oral vowel and a nasal consonant. Just in general if we can remove (well, reduce) the noise and variability in the pronunciation dictionary, we can constrain the problem space and learn better models.
The solution in the current version of MFA 2.0 is to allow the user to
specify dictionaries by speaker
. So we can say given a speaker and transcript, here is a much smaller list of pronunciation variants that can be chosen. To do this, MFA accepts a
.yaml
file as an argument to the dictionary path which will be parsed as a mapping between speakers and dictionaries. So the command below
::bash
mfa train /path/to/corpus /path/to/dictionary.txt /path/to/output_directory
becomes
::bash
mfa train /path/to/corpus /path/to/speaker_dictionaries.yaml /path/to/output_directory
Where
/path/to/speaker_dictionaries.yaml
is a file that looks like:
::yaml
default: english_ipa
uk_speaker_one: /path/to/english_uk_ipa.txt
uk_speaker_two: /path/to/english_uk_ipa.txt
The only requirement is that one key specifies the
default
dictionary, which will be used for all speakers that do not have an explicit dictionary.
Multilingual IPA mode ¶
Multilingual IPA mode
is a flag specified during training that transforms IPA characters when parsing the dictionary. The idea is to preserve quality contrasts and remove length markers (i.e., collapse long and short vowels) and to split digraphs into their component sounds (i.e., split
/eɪ
tʃ/
into
/e
ɪ
t
ʃ/
). One consequence of splitting digraphs is the minimum duration for these sounds will be greater (60ms rather than 30ms), but given the dynamics and complexities of these sounds, I think that’s a reasonable condition on them. Triphthongs, like in Mandarin, will likewise be split into three separate vowels.
The list of diacritics that multilingual IPA mode will strip are:
|
Diacritic |
Description |
Example Input |
Example Output |
|---|---|---|---|
|
◌ː |
Long |
iː |
i |
|
◌ˑ |
Half-long |
iˑ |
i |
|
◌̆ |
Extra short |
ĭ |
i |
|
◌̩ |
Syllabic |
m̩ |
m |
|
◌̯ ◌̑ |
Non-syllabic |
ʊ̯ |
ʊ |
|
◌͡◌ |
Linking, not necessary in MFA because phones are delimited by spaces |
t͡ʃ |
tʃ |
|
◌‿◌ |
Linking, not necessary in MFA because phones are delimited by spaces |
t‿ʃ |
tʃ |
|
◌͜◌ |
Linking, not necessary in MFA because phones are delimited by spaces |
t͜ʃ |
tʃ |
The following are the default digraph patterns for English. Note that digraph splitting happens after removing the diacritics above, so in cases of affricates with linking bars, the bar will be removed and then the component characters will be split.
|
Digraph pattern |
Description |
Example Input |
Example Output |
|---|---|---|---|
|
[dt][szʒʃʐʑʂɕç] |
Affricates |
tʃ |
t ʃ |
|
[aoɔe][ʊɪ] |
Diphthongs |
ɔɪ |
ɔ ɪ |
The above settings are primarily useful for the IPA English dictionary that I’m working on . To modify the settings, simply create a train_config.yaml and add/modify the following settings as necessary:
::yaml
strip_diacritics:
- "ː" # long, i.e. /ɑː/
- "ˑ" # half long, i.e. /ɑˑ/
- "̆" # extra short, i.e. /ĭ/
- "̯" # non syllabic, i.e. /i̯/
- "͡" # linking, i.e. /d͡ʒ/
- "‿" # linking, i.e. /d‿ʒ/
- "͜" # linking, i.e. /d͜ʒ/
- "̩" # syllabic, i.e. /n̩/
digraphs:
- "[dt][szʒʃʐʑʂɕç]" # affricates
- "[aoɔe][ʊɪ]" # diphthongs
The digraphs will be parsed into regular expressions, so you can use Python’s re syntax to specify any additional patterns that should be split into separate characters.
One final thing important to note is that the modifications are all internal to the aligner. When the output TextGrids are generated, the original pronunciation is used to reconstruct the output, so split digraphs will be fused back together and remove the phone-internal boundaries and diacritics will be added back in.
Evaluating the multilingual mode ¶
Even though the Buckeye corpus is monolingual English corpus, we can use it to evaluate improvements that multilingual mode provide. The measures here are the same ones that I used in the updated MFA metrics blog post . The plot below shows the word boundary error across the Buckeye corpus. For comparison, I’ve included some default models from the metrics post.

The word boundaries are pretty consistent across the three training conditions. The consistency is likely the result of learning good representations of silence in the Buckeye corpus.

Phone boundaries in the CVC words show pretty comparable rates, but in general nothing very conclusive. However, looking at phone errors across the whole of the corpus, we see improved phone boundary accuracy for the multilingual trained mode.

Multilingual mode looks pretty good! It shows some additional improvements over just the IPA dictionary, but it’s pretty slight.
Combining multilingual IPA and speaker dictionaries ¶
One of my major side projects is to create a corpus of esports (professional video games) casting, which is a good test case for these new features. As an aside, a key feature of esports casting is that it is a broadcast style of spontaneous where speakers are reacting to events in game in real time.Vocabulary is much more restricted than general spontaneous speech, with in-game character and ability names repeated often, as well as player and team names. There are usually two casters that trade off turns, with a “play-by-play caster” that walks viewers through the low-level action and a “color caster” that does more analytical commentary about the bigger picture aspects of the match during any downtimes between high intensity moments. Relevant to the new features, each caster has their own accent, with representation across British, Australian, New Zealand, and American varieties, along with many non-native speakers.
Below is an example alignment in the corpus of speech by Sideshow, who is a British English speaker who does casting in Overwatch.
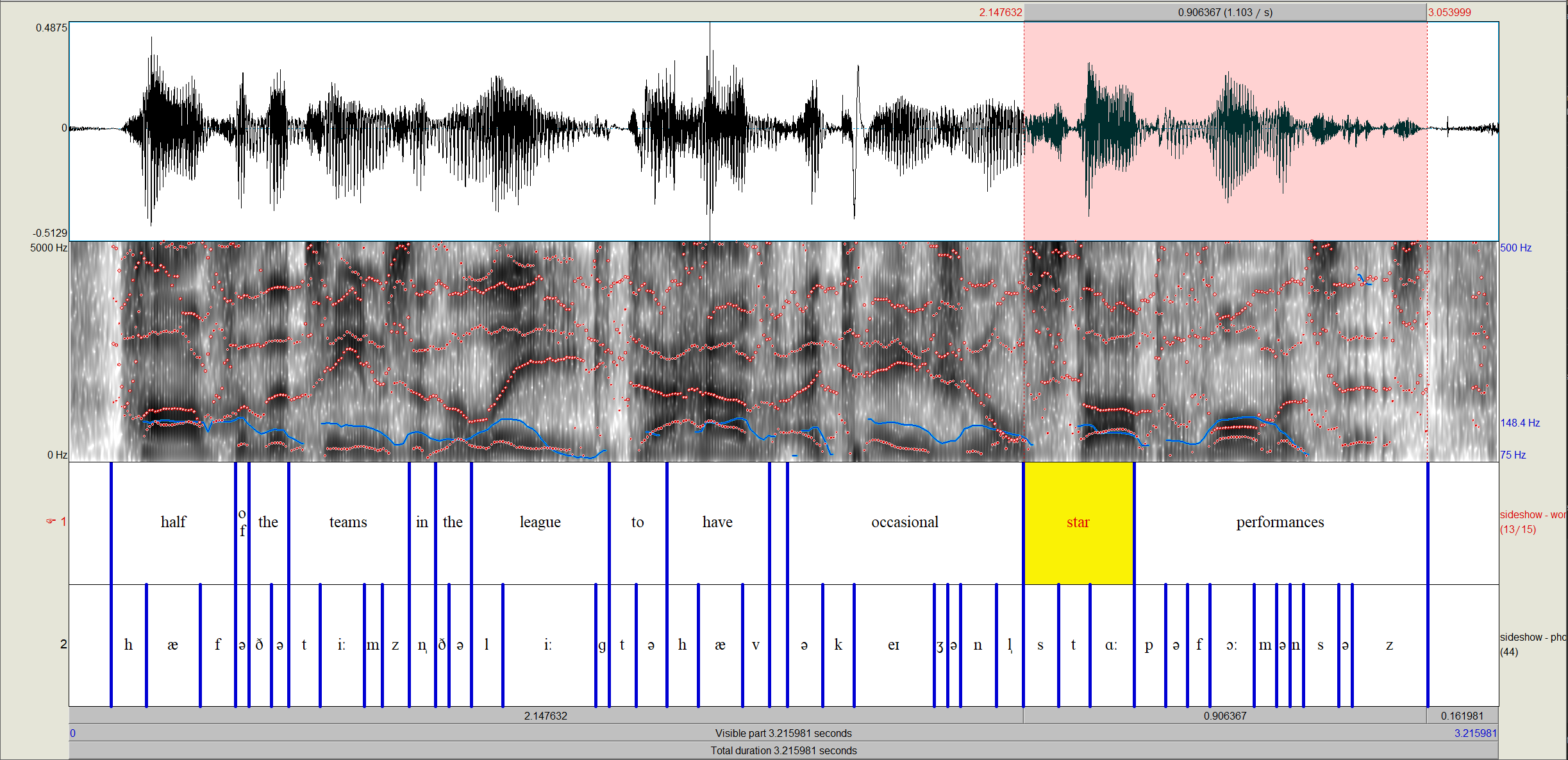
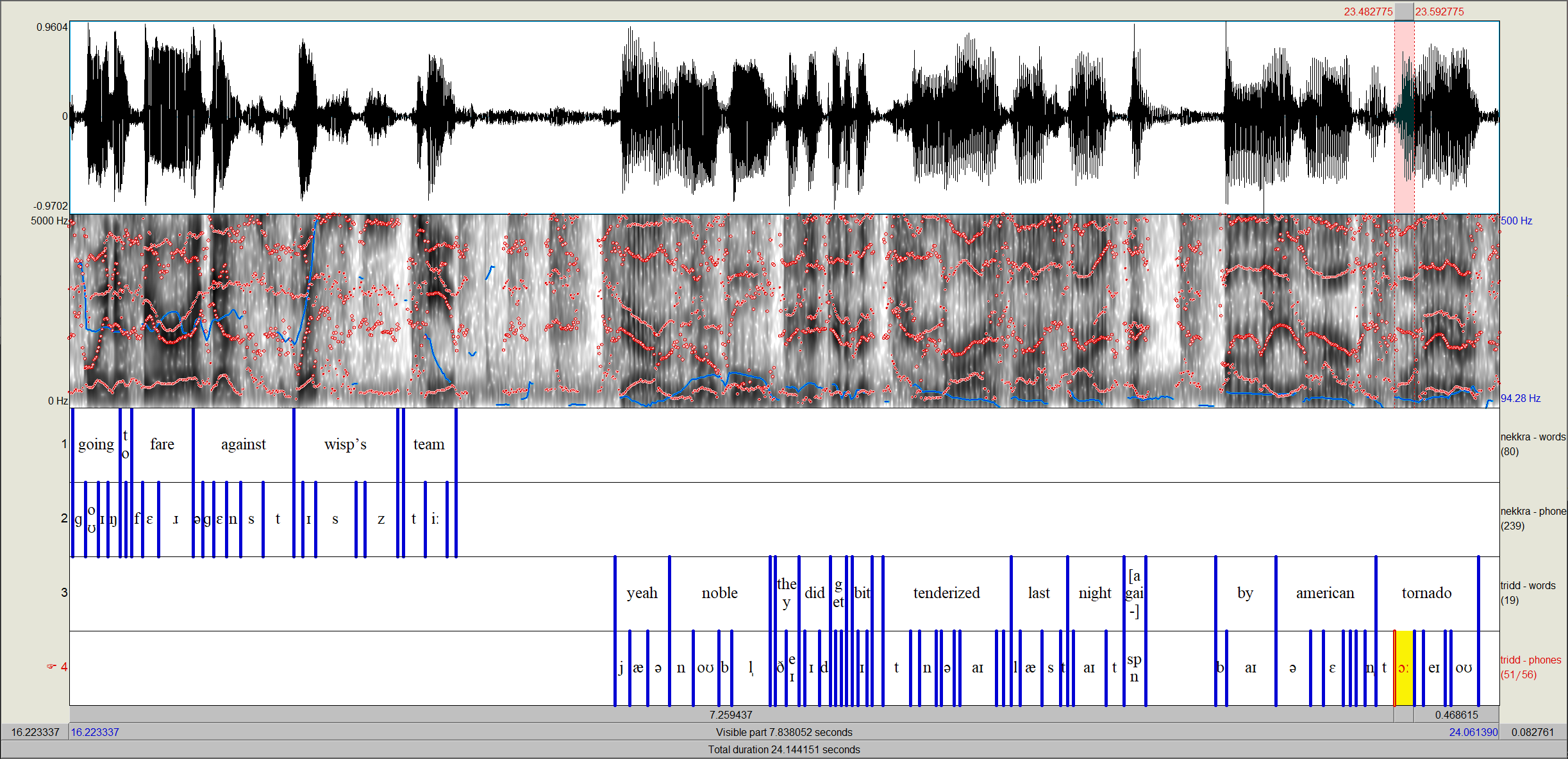
The above can be achieved with a single dictionary, of course, but what’s handy is being able to align a single file with speakers of different dialects (or languages). In the below example, there are two Overwatch casters, Nekkra and Tridd. Nekkra is a speaker of American English, whereas Tridd speaks a British dialect.
Summing up ¶
So that was a brief look into a couple of new features targeting datasets that use different speech varieties, either multiple dialects or multiple languages, with the same phone set. Multilingual IPA uses an internal representation of a simplified phone set to maximize similarities and reduce complexity while recombining and formatting the output to match the pronunciation dictionary representations. Speaker dictionaries allow for specifying pronunciation dictionaries to vary by speaker, while still sharing a single acoustic model, so the overall modelling should be more accurate and alignments better. The actual projects that I’m using these features for are still very much in progress, but hopefully these features will be helpful for you!